Bayesian Preference Estimation with Inconsistent Feedback
Manuscript submitted for review to the DECISION Journal
This website contains access to data, code, and results for the paper “Bayesian Preference Estimation with Inconsistent Feedback,” submitted to the journal of Mathematical Psychology.
To foster reproducibility, we have made all code and results publicly available in our repository : Repository link
Datasets
There are three datasets used in this paper with the following statistics:
| Dataset | Number of Users | Number of Items | Number of Interactions | Number of Categories | % Sparsity |
|---|---|---|---|---|---|
| Yelp | 6,651 | 8,267 | 264,174 | 265 | 99.55% |
| MovieLens1M | 6,040 | 3,260 | 998,538 | 18 | 94.93% |
| MovieLensSmall | 610 | 8,974 | 100,010 | 19 | 98.17% |
Sample data snapshot - from MovieLens dataset:
| UserID | movieID | Like Status | Primary Genre | Secondary Genre | Movie Name |
|---|---|---|---|---|---|
| 54462 | 288 | 0 | Adventure | Comedy | The Princess Bride |
| 20948 | 247 | 0 | Action | Adventure | Indiana Jones |
| 25386 | 401 | 0 | Action | Adventure | Mad Max: Fury Road |
| 48678 | 491 | 1 | Comedy | Drama | The Truman Show |
| 42717 | 322 | 1 | Crime | Drama | The Godfather |
| 52687 | 143 | 0 | Adventure | Drama | Life of Pi |
| 66403 | 218 | 0 | Action | Adventure | Gladiator |
| 41867 | 130 | 1 | Drama | Thriller | Se7en |
| 10548 | 69 | 0 | Action | Drama | Inception |
| 58166 | 33 | 0 | Action | Comedy | Guardians of the Galaxy |
From Yelp Dataset:
| UserID | LocationID | Like Status | Type of Location | City |
|---|---|---|---|---|
| 155 | 442 | 0 | Cinema | San Francisco |
| 1734 | 6273 | 1 | Cinema | New York |
| 231 | 3004 | 1 | Restaurant | Los Angeles |
| 787 | 3475 | 1 | Shopping Center | San Francisco |
| 2293 | 1857 | 1 | Cinema | San Francisco |
| 1643 | 364 | 0 | Restaurant | Chicago |
| 565 | 2669 | 0 | Restaurant | San Francisco |
| 5013 | 6758 | 0 | Shopping Center | Los Angeles |
| 3500 | 429 | 0 | Shopping Center | Chicago |
| 605 | 4223 | 1 | Restaurant | Los Angeles |
Process Data Download Instruction
The raw data for this work can be downloaded from this link, separated by train, test, and category datasets.
Three folders are included, each folder contain data for one of the datasets (folders are MovieLens1M, MovieLensSmall, Yelp)
Models Evaluated
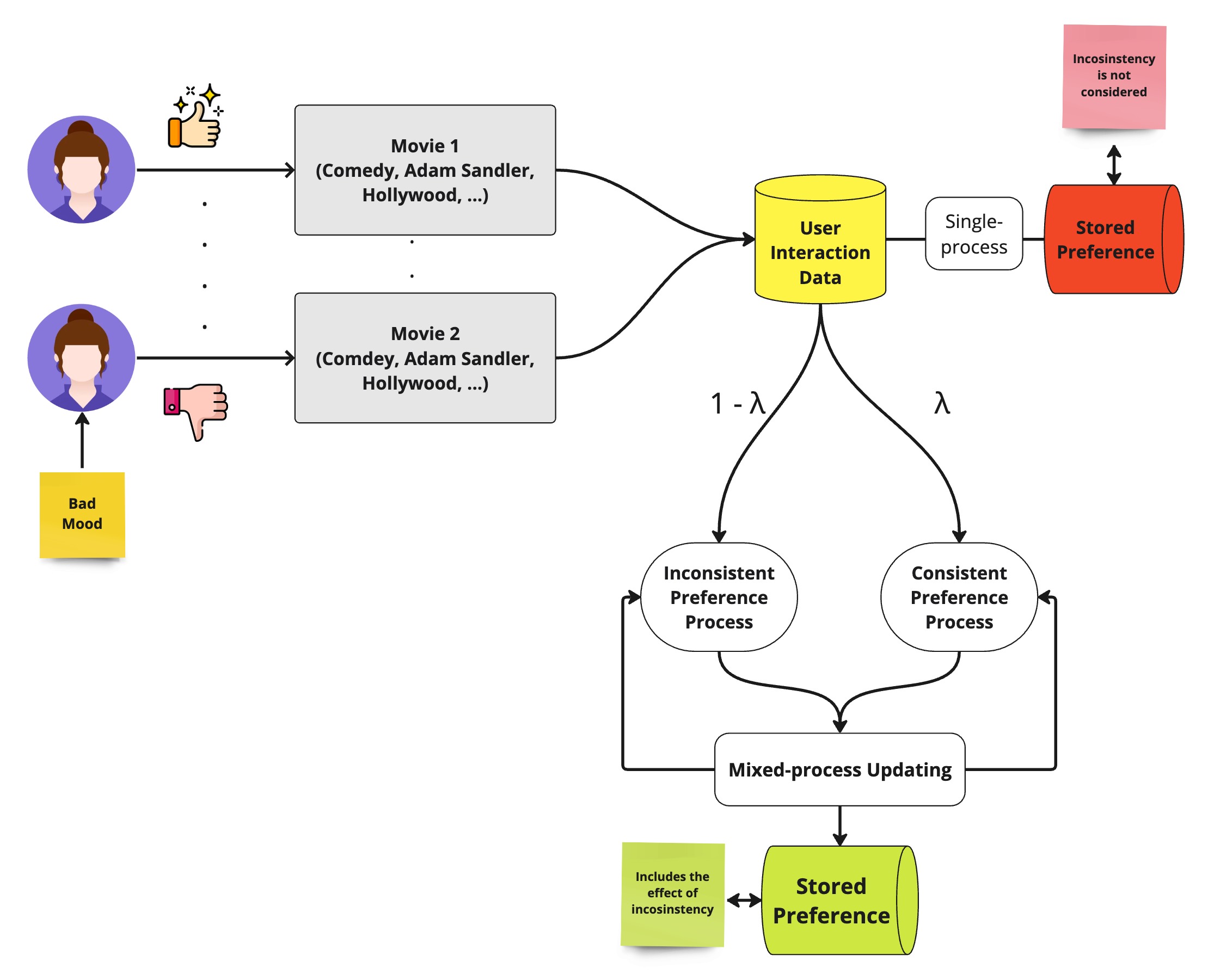
In this research, we evaluate the performance of our proposed model by comparing it against several well-known baseline models. These models include advanced machine learning techniques and established Bayesian methods. Unlike our proposed model, these baselines do not explicitly account for user inconsistency.
1. Bayesian Updating Model
This model employs Bayesian inference to update the parameters of a Beta distribution for each user-attribute pair based on binary feedback (e.g., like/dislike).
2. Bayesian Personalized Ranking (BPR)
BPR is designed for optimizing ranking tasks with implicit feedback, such as clicks or purchases, rather than explicit ratings.
3. Collaborative Filtering Model
This model predicts user ratings by leveraging ratings from similar users and items, combining information from multiple sources.
4. Multi-Attribute Utility Model
This model estimates user preferences by calculating the utility of items based on multiple attributes.
5. Most Popular Model (MostPop)
The MostPop model recommends items based on their overall popularity, serving as a baseline for comparison.
Notebooks
For simplicity and reproduciblitiy, three easy-to-run notebooks are provided:
1. Model_implementation.ipynb
This notebook demonstrates the implementation of all baseline models. It creates simulated data and runs all baseline and proposed models on this simulated data. Additionally, it includes ablation studies on item scarcities, user scarcities, and users with varying degrees of inconsistencies.
2. Results.ipynb
This notebook utilizes the saved and uploaded results from all simulated datasets as well as the three real-world datasets. It analyzes the results by plotting different statistics and outcomes of the proposed model and baseline models.
3. Main.ipynb
This notebook combines the entire process, including model implementation, running the model on both simulated and real-world datasets, and performing evaluations.
Results
Results on real-data can be seen below:
Metrics are calculated based on the top-10 predictions in the test set. The best-performing model for each metric is highlighted in bold, and the second-best is italicized.
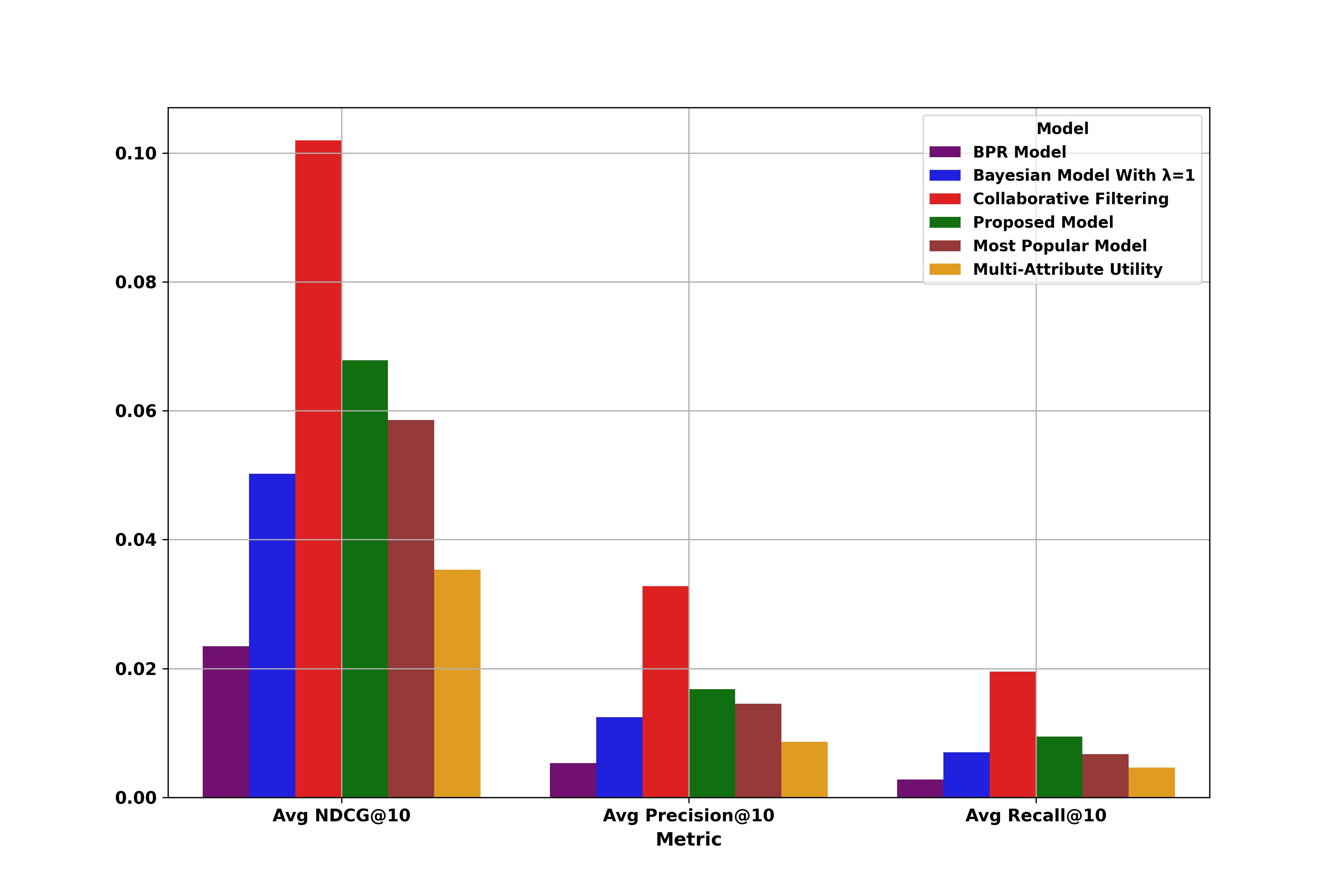
MovieLens 1M
| Model | Precision@10 | Recall@10 | NDCG@10 | F1@10 |
|---|---|---|---|---|
| Bayesian Model | 1.2434 | 0.6991 | 5.0201 | 0.8950 |
| Collaborative Filtering | 3.2814 | 1.9516 | 10.1953 | 2.4475 |
| Multi-Attribute Utility | 0.8642 | 0.4642 | 3.5332 | 0.6039 |
| BPR Model | 0.5315 | 0.2795 | 2.3449 | 0.3663 |
| Most Popular Model | 1.4520 | 0.6706 | 5.8587 | 0.9175 |
| Mixture Bayesian Model | 1.6803 | 0.9418 | 6.7846 | 1.2070 |
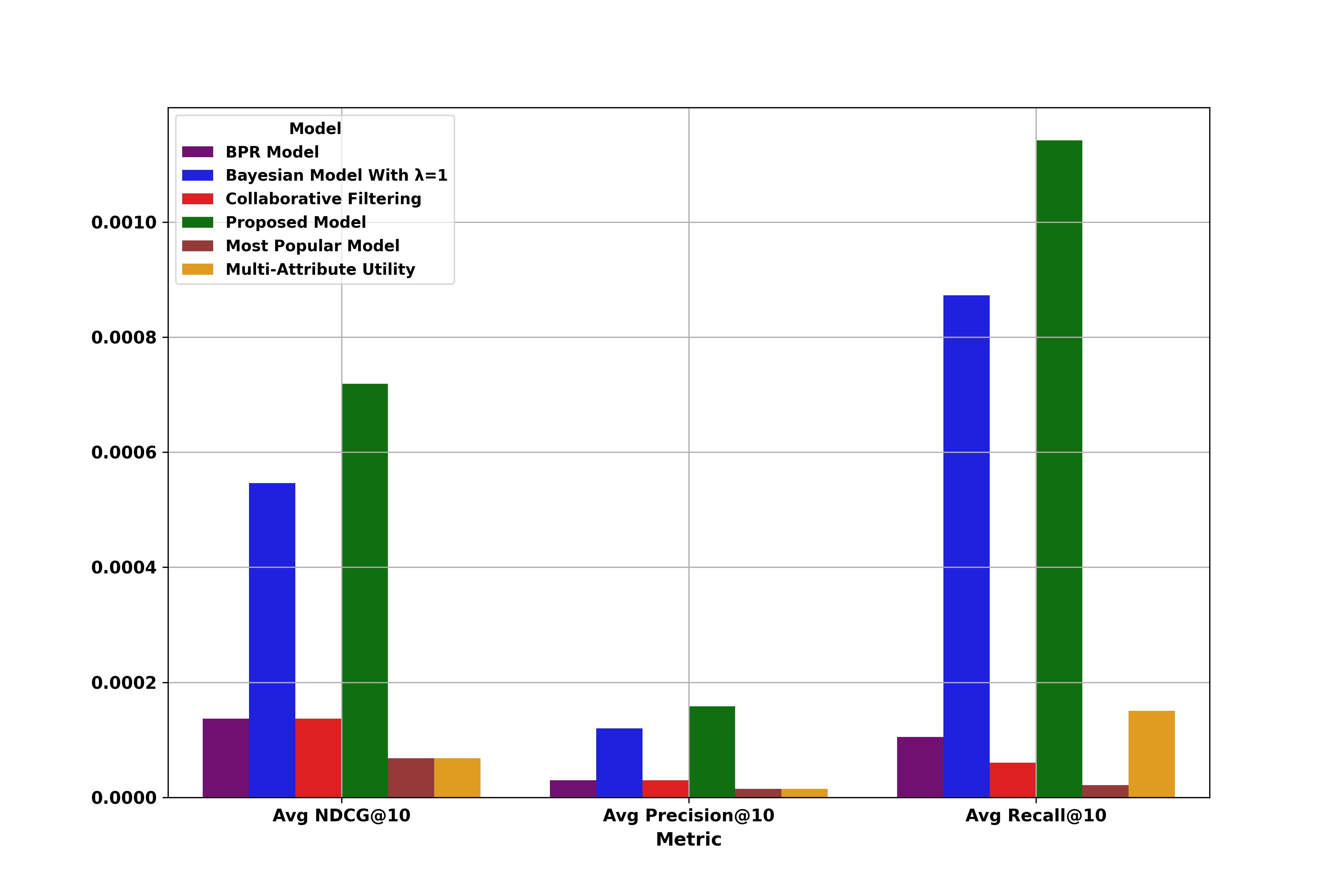
Yelp
| Model | Precision@10 | Recall@10 | NDCG@10 | F1@10 |
|---|---|---|---|---|
| Bayesian Model | 0.0120 | 0.0872 | 0.0547 | 0.0211 |
| Collaborative Filtering | 0.0030 | 0.0060 | 0.0137 | 0.0040 |
| Multi-Attribute Utility | 0.0015 | 0.0150 | 0.0068 | 0.0027 |
| BPR Model | 0.0030 | 0.0105 | 0.0137 | 0.0047 |
| Most Popular Model | 0.0015 | 0.0021 | 0.0068 | 0.0018 |
| Mixture Bayesian Model | 0.0158 | 0.1142 | 0.0719 | 0.0278 |
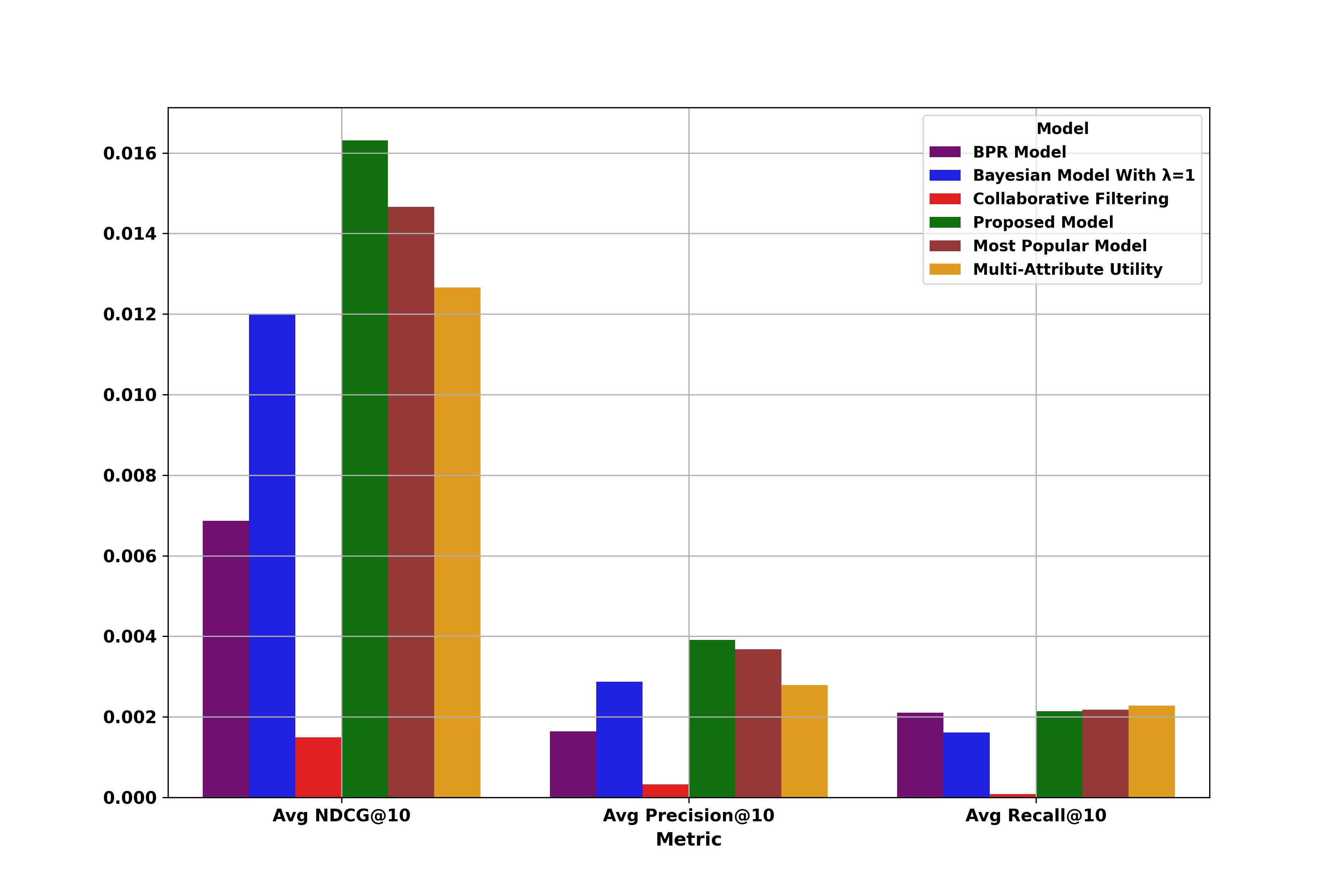
MovieLens Small
| Model | Precision@10 | Recall@10 | NDCG@10 | F1@10 |
|---|---|---|---|---|
| Bayesian Model | 0.2874 | 0.1609 | 1.2000 | 0.2063 |
| Collaborative Filtering | 0.0328 | 0.0086 | 0.1490 | 0.0136 |
| Multi-Attribute Utility | 0.2787 | 0.2283 | 1.2662 | 0.2510 |
| BPR Model | 0.1639 | 0.2101 | 0.6872 | 0.1842 |
| Most Popular Model | 0.3683 | 0.2178 | 1.4661 | 0.2738 |
| Mixture Bayesian Model | 0.3915 | 0.2140 | 1.6312 | 0.2767 |